
Roblox Studio ได้กลายเป็นพื้นที่ทดสอบสำหรับผู้ช่วย AI (เอไอ) แบบ agentic (เอเจนติก) มากขึ้นเรื่อยๆ ซึ่งออกแบบมาเพื่อช่วยให้ผู้สร้างพัฒนาเกมได้เร็วขึ้น แม้ว่าเครื่องมือเหล่านี้จะสามารถเขียนสคริปต์ (script) แทรกแอสเซ็ต (asset) และปรับเปลี่ยนสภาพแวดล้อมได้แล้ว แต่การวัดว่าเครื่องมือเหล่านี้ทำงานได้ดีเพียงใดในสถานการณ์การพัฒนาจริงนั้นเป็นเรื่องยาก OpenGameEval มีเป้าหมายที่จะแก้ไขปัญหานั้นด้วยการนำเสนอเฟรมเวิร์ก (framework) ดั้งเดิมของ Roblox Studio สำหรับการประเมินผู้ช่วย AI ภายใต้เงื่อนไขที่สมจริง
OpenGameEval พัฒนาโดย Tiantian Zhang, Kartik Ayyar, Mengsha Sun และ Lynn Gong โดยถูกวางตำแหน่งให้เป็นระบบการประเมินแรกที่สร้างขึ้นโดยตรงจากเวิร์กโฟลว์ (workflow) ของ Roblox Studio แทนที่จะแยกส่วนย่อยของโค้ด (code snippet) หรืออาศัยพรอมต์ (prompt) แบบไร้สถานะ (stateless) แต่จะรันโมเดล (model) AI ภายในเซสชัน (session) การแก้ไขและเล่นที่จำลองขึ้นมา ซึ่งคล้ายคลึงกับวิธีการทำงานของผู้สร้างจริง
เหตุใดเกณฑ์มาตรฐานแบบดั้งเดิมจึงไม่เพียงพอสำหรับ Roblox
เกณฑ์มาตรฐาน AI ที่มีอยู่ส่วนใหญ่จะเน้นไปที่ปัญหาการเขียนโค้ด (coding) ที่แคบ โดยมีอินพุต (input) และเอาต์พุต (output) ที่กำหนดไว้อย่างชัดเจน การพัฒนา Roblox ไม่ค่อยเข้ากับรูปแบบนั้น เกมถูกสร้างขึ้นภายในโลก 3 มิติที่คงอยู่ ซึ่งสคริปต์ (script) จะโต้ตอบกับลำดับชั้นของวัตถุ, เครือข่ายผู้เล่นหลายคน (multiplayer networking) และขอบเขตไคลเอนต์-เซิร์ฟเวอร์ (client-server boundaries) การเปลี่ยนแปลงที่ทำในส่วนหนึ่งของประสบการณ์มักจะขึ้นอยู่กับบริบทที่กระจัดกระจายอยู่ทั่วสคริปต์และอินสแตนซ์ (instance) หลายรายการ
OpenGameEval ถูกสร้างขึ้นเพื่อตอบสนองต่อข้อจำกัดเหล่านี้ เป้าหมายคือการทดสอบว่าผู้ช่วย AI สามารถใช้เหตุผลผ่านสภาพแวดล้อม Roblox ที่ใช้งานอยู่ เข้าใจตรรกะที่มีอยู่ และทำการเปลี่ยนแปลงที่คงอยู่เมื่อเกมถูกรันจริงได้หรือไม่ แนวทางนี้จะเปลี่ยนการประเมินจากการแก้ไขทางทฤษฎีไปสู่ประโยชน์ใช้สอยจริงสำหรับผู้สร้าง
เจาะลึกเฟรมเวิร์ก OpenGameEval
หัวใจหลักของ OpenGameEval คือการสร้าง สภาพแวดล้อมการพัฒนา Roblox Studio ขึ้นมาใหม่ในลักษณะที่สามารถทำซ้ำได้ การประเมินแต่ละครั้งจะจำลองทั้งพฤติกรรมในเวลาแก้ไขและเวลาเล่น เพื่อให้มั่นใจว่าฟิสิกส์ (physics) เครือข่าย (networking) และการโต้ตอบแบบผู้เล่นหลายคน (multiplayer interactions) ทำงานได้ตรงตามที่ควรจะเป็นในโปรเจกต์ (project) จริง สิ่งนี้ช่วยให้ผู้ประเมินสามารถสังเกตได้ว่าการเปลี่ยนแปลงของผู้ช่วย AI ส่งผลต่อประสบการณ์อย่างไรเมื่อมันทำงาน ไม่ใช่แค่ว่าโค้ด (code) คอมไพล์ (compile) ได้หรือไม่
เฟรมเวิร์ก (framework) ยังรวมถึงการจำลองอินพุต (input simulation) ซึ่งทำให้สามารถเรียกใช้การกระทำของผู้เล่น เช่น การเคลื่อนไหว การกดปุ่ม และการเปลี่ยนกล้อง (camera) ระหว่างการทดสอบ สิ่งนี้มีความสำคัญอย่างยิ่งสำหรับการประเมินคุณสมบัติที่เผยให้เห็นปัญหาผ่านการโต้ตอบเท่านั้น ฟังก์ชัน (function) ทั้งหมดนี้ถูกเปิดเผยผ่าน API (เอพีไอ) แบบรวม ทำให้ทีมวิจัยสามารถเปรียบเทียบโมเดลภาษาขนาดใหญ่ (large language model) ที่แตกต่างกันในชุดงานเดียวกันได้ง่ายขึ้น
การทดสอบสถานการณ์การพัฒนาจริง ไม่ใช่แค่ส่วนย่อยของโค้ด
ชุดข้อมูลเกณฑ์มาตรฐาน OpenGameEval ในปัจจุบันประกอบด้วยกรณีทดสอบที่สร้างขึ้นด้วยมือ 47 กรณีทดสอบ แต่ละกรณีอิงตามงานพัฒนา Roblox ทั่วไป รวมถึงกลไกเกม (game mechanics) การตั้งค่าสภาพแวดล้อม (environment setup) แอนิเมชัน (animation) ส่วนต่อประสานผู้ใช้ (user interfaces) และเสียง (sound) สถานการณ์เหล่านี้ถูกสร้างและตรวจสอบโดยผู้เชี่ยวชาญในสาขาเพื่อให้แน่ใจว่าสะท้อนถึงเวิร์กโฟลว์ (workflow) ของผู้สร้างจริง
แตกต่างจากความท้าทายในการเขียนโค้ด (coding) แบบดั้งเดิม การทดสอบเหล่านี้เป็นแบบ end-to-end (เอนด์ทูเอนด์) ผู้ช่วย AI ที่ประสบความสำเร็จจะต้องค้นหาสคริปต์ (script) ที่เกี่ยวข้อง ตีความตรรกะที่มีอยู่ ตัดสินใจว่าโค้ด (code) ใหม่ควรอยู่ตรงไหน และนำการเปลี่ยนแปลงที่ใช้งานได้ทั้งในฝั่งไคลเอนต์ (client) และเซิร์ฟเวอร์ (server) มาใช้ การให้คะแนนจะดำเนินการผ่านการทดสอบหน่วยที่สามารถดำเนินการได้ (executable unit test) และเมตริก (metric) มาตรฐาน เช่น pass@k ทำให้สามารถทำซ้ำผลลัพธ์และเปรียบเทียบระหว่างโมเดล (model) ได้
บริบทเปลี่ยนแปลงความยากได้อย่างไร
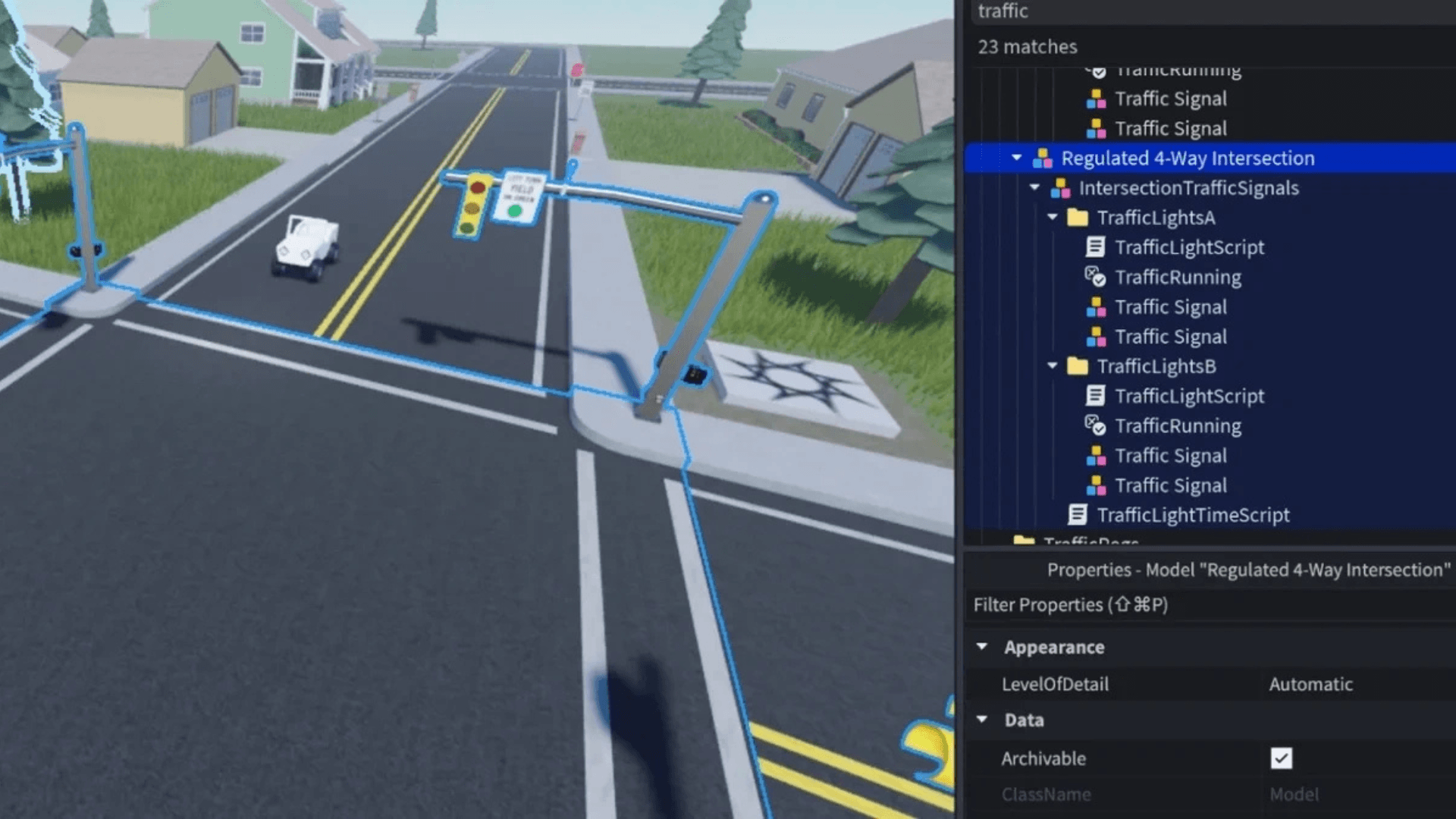
หนึ่งในคุณสมบัติที่โดดเด่นของ OpenGameEval คือการมุ่งเน้นไปที่ความหลากหลายทางบริบท พรอมต์ (prompt) เดียวกันสามารถประเมินได้ในสภาพแวดล้อมที่แตกต่างกันหลายแบบ ซึ่งแตกต่างกันในด้านโครงสร้างและความซับซ้อน ตัวอย่างเช่น งานที่เกี่ยวข้องกับไฟจราจรสี่แยกอาจถูกทดสอบในไฟล์ตำแหน่งที่ว่างเปล่า ฉากชานเมืองที่มีประชากร หรือการตั้งค่าที่รวมทั้งสัญญาณไฟจราจรและสัญญาณคนเดินเท้า การเปลี่ยนแปลงแต่ละครั้งบังคับให้ผู้ช่วย AI ต้องปรับการใช้เหตุผลตามสิ่งที่มีอยู่แล้วในประสบการณ์
งานที่ซับซ้อนมากขึ้น เช่น การนำระบบฟื้นฟูพลังชีวิตมาใช้ กำหนดให้โมเดล (model) ต้องติดตามตรรกะความเสียหายในสคริปต์ (script) ต่างๆ กำหนดว่าควรทำการเปลี่ยนแปลงบนเซิร์ฟเวอร์ (server) หรือไคลเอนต์ (client) และตรวจสอบให้แน่ใจว่าการกำหนดเวลาและการจำลองแบบ (replication) ทำงานได้อย่างถูกต้อง สถานการณ์เหล่านี้ได้รับการออกแบบมาเพื่อเปิดเผยว่าผู้ช่วย AI สามารถรักษาบริบทในหลายขั้นตอนได้หรือไม่ แทนที่จะอาศัยการจับคู่รูปแบบในระดับผิวเผิน
ผลลัพธ์เบื้องต้นชี้ให้เห็นถึงข้อจำกัดในปัจจุบัน
ผลลัพธ์เบื้องต้นจาก OpenGameEval ชี้ให้เห็นถึงความแตกต่างที่ชัดเจนในความสามารถของ AI ในปัจจุบัน โมเดล (model) มักจะทำงานได้ดีในงานย่อยที่เกี่ยวข้องกับการจัดการโดยตรงของอินสแตนซ์ (instance) หรือคุณสมบัติเดียว การกระทำต่างๆ เช่น การปรับพลังการกระโดดของผู้เล่น หรือการกำหนดค่าเอฟเฟกต์อนุภาค (particle effect) มักจะประสบความสำเร็จด้วยความน่าเชื่อถือสูง
ประสิทธิภาพลดลงอย่างรวดเร็วเมื่อภารกิจต้องใช้การใช้เหตุผลเชิงบริบทที่ลึกซึ้งยิ่งขึ้น สถานการณ์ที่เกี่ยวข้องกับการเปลี่ยนแปลงที่ประสานกันในสคริปต์ (script) การกรองวัตถุที่เกี่ยวข้องอย่างระมัดระวัง หรือความเข้าใจพฤติกรรมของผู้เล่นหลายคน (multiplayer behavior) ยังคงให้ผลลัพธ์ที่ประสบความสำเร็จต่ำ ผลลัพธ์เหล่านี้เน้นย้ำว่ายังมีช่องว่างให้ปรับปรุงอีกมากก่อนที่ผู้ช่วย AI จะสามารถจัดการงานพัฒนา Roblox ที่ซับซ้อนได้อย่างน่าเชื่อถือด้วยตัวเอง
สัญญาณของความก้าวหน้าอย่างต่อเนื่อง
แม้จะมีความท้าทายเหล่านี้ OpenGameEval ได้บันทึกสัญญาณของการปรับปรุงแล้วเมื่อโมเดล (model) พัฒนาขึ้น ในงานหนึ่งที่เกี่ยวข้องกับการเปลี่ยนสีโลโก้ Roblox โมเดล (model) รุ่นแรกๆ ล้มเหลวเนื่องจากวัตถุไม่ได้ถูกตั้งชื่ออย่างชัดเจน การประเมินล่าสุดแสดงให้เห็นว่าโมเดลบางตัวสามารถระบุวัตถุที่ถูกต้องได้สำเร็จโดยการตรวจสอบคุณสมบัติและตำแหน่งในลำดับชั้นของอินสแตนซ์ (instance hierarchy) แทนที่จะอาศัยเพียงแค่ข้อกำหนดการตั้งชื่อ
การปรับปรุงทีละน้อยเหล่านี้ชี้ให้เห็นว่าผู้ช่วย AI กำลังพัฒนาความสามารถในการใช้เหตุผลเชิงโครงสร้างภายในสภาพแวดล้อมของเกมอย่างช้าๆ แม้ว่าความเข้าใจในบริบทที่กว้างขึ้นจะยังคงไม่สอดคล้องกันก็ตาม
OpenGameEval มีความหมายอย่างไรต่อผู้สร้างและนักวิจัย
OpenGameEval ได้รับการออกแบบมาเพื่อให้บริการทั้งผู้สร้าง Roblox และชุมชนนักวิจัย AI ในวงกว้าง กระดานผู้นำสาธารณะแสดงให้เห็นถึงประสิทธิภาพของโมเดล (model) ต่างๆ ในหมวดหมู่ต่างๆ เช่น การสร้างโค้ด (code generation) และการใช้เครื่องมือ สำหรับนักวิจัย เฟรมเวิร์ก (framework) นี้เป็นวิธีมาตรฐานในการดำเนินการประเมินที่สามารถทำซ้ำได้ภายในสภาพแวดล้อมของเอนจินเกม (game engine) จริง
ในอนาคต ทีมงานเบื้องหลัง OpenGameEval วางแผนที่จะขยายชุดข้อมูล ปรับปรุงเครื่องมือประเมิน และรวบรวมความคิดเห็นจากชุมชนผู้สร้าง เป้าหมายระยะยาวคือการสร้างจุดอ้างอิงร่วมกันสำหรับการวัดความก้าวหน้าของ AI แบบ agentic (เอเจนติก) สำหรับการพัฒนาเกม รวมถึงแอปพลิเคชัน (application) ในอนาคตที่เชื่อมโยงกับเศรษฐกิจผู้สร้างสไตล์ web3 (เว็บทรี)
ตรวจสอบ Roblox Gift Cards บน Amazon ได้ที่นี่
เรียนรู้เกี่ยวกับ Roblox experiences ยอดนิยมอื่นๆ ได้ที่นี่:
คำถามที่พบบ่อย (FAQs)
OpenGameEval คืออะไร?
OpenGameEval คือเฟรมเวิร์ก (framework) การประเมินแบบโอเพนซอร์ส (open-source) และเกณฑ์มาตรฐานที่ออกแบบมาเพื่อทดสอบผู้ช่วย AI โดยตรงภายใน Roblox Studio โดยจะวัดว่าโมเดล (model) ทำงานได้ดีเพียงใดในงานพัฒนาจริง แทนที่จะเป็นปัญหาการเขียนโค้ด (coding) ที่แยกส่วน
OpenGameEval แตกต่างจากเกณฑ์มาตรฐาน AI อื่นๆ อย่างไร?
แตกต่างจากเกณฑ์มาตรฐานแบบดั้งเดิม OpenGameEval จะดำเนินการประเมินในสภาพแวดล้อม Roblox Studio ที่จำลองขึ้นมา สิ่งนี้ช่วยให้สามารถทดสอบการใช้เหตุผลเชิงบริบท พฤติกรรมของผู้เล่นหลายคน (multiplayer behavior) และการโต้ตอบแบบมีสถานะ (stateful interaction) ซึ่งเป็นเรื่องปกติในการพัฒนาเกม
OpenGameEval มีงานประเภทใดบ้าง?
เกณฑ์มาตรฐานประกอบด้วยงานที่เกี่ยวข้องกับกลไกเกม (game mechanics) การเขียนสคริปต์ (scripting) การสร้างสภาพแวดล้อม (environment building) แอนิเมชัน (animation) ส่วนต่อประสานผู้ใช้ (user interfaces) และเสียง (sound) งานหลายอย่างต้องใช้การใช้เหตุผลหลายขั้นตอนในสคริปต์ (script) และวัตถุหลายรายการ
ใครสามารถใช้ OpenGameEval ได้บ้าง?
เฟรมเวิร์ก (framework) นี้เป็นโอเพนซอร์ส (open source) และมีไว้สำหรับนักวิจัย AI นักพัฒนาเครื่องมือ และทีมที่สร้างหรือประเมินผู้ช่วย AI สำหรับ Roblox Studio
เหตุใด OpenGameEval จึงมีความสำคัญต่อผู้สร้าง Roblox?
ด้วยการให้ข้อมูลประสิทธิภาพที่โปร่งใสและการประเมินที่สมจริง OpenGameEval ช่วยให้ผู้สร้างเข้าใจจุดแข็งและข้อจำกัดของผู้ช่วย AI และติดตามว่าเครื่องมือเหล่านี้พัฒนาขึ้นอย่างไรเมื่อเวลาผ่านไป





