
Roblox Studio 已经逐渐成为代理式 AI 助手的试验场,这些助手旨在帮助创作者更快地开发游戏。虽然这些工具已经可以编写脚本、插入素材和修改环境,但衡量它们在实际开发场景中的表现一直很困难。OpenGameEval 旨在通过引入一个 Roblox Studio 原生框架来解决这个问题,该框架用于在真实条件下评估 AI 助手。
OpenGameEval 由 Tiantian Zhang、Kartik Ayyar、Mengsha Sun 和 Lynn Gong 开发,被定位为第一个直接围绕 Roblox Studio 工作流程构建的评估系统。它不是隔离代码片段或依赖无状态提示,而是在模拟的编辑和游戏会话中运行 AI 模型,这些会话与创作者实际工作的方式非常相似。
为什么传统基准测试不适用于 Roblox
大多数现有的 AI 基准测试都侧重于具有明确输入和输出的狭窄编码问题。Roblox 的开发很少符合这种模式。游戏是在持久的 3D 世界中构建的,脚本与对象层次结构、多人网络和客户端-服务器边界交互。在一个体验中进行的更改通常取决于分散在多个脚本和实例中的上下文。
OpenGameEval 正是为了应对这些局限性而创建的。它的目标是测试 AI 助手是否能够在一个实时的 Roblox 环境中进行推理,理解现有逻辑,并进行在游戏实际运行时能够保持稳定的更改。这种方法将评估从理论正确性转向了对创作者的实际有用性。
OpenGameEval 框架详解
OpenGameEval 的核心是以可复现的方式重现 Roblox Studio 开发环境。每次评估都模拟编辑时和游戏时行为,确保物理、网络和多人交互与真实项目中的行为完全一致。这使得评估者能够观察 AI 助手的更改在体验运行后产生的影响,而不仅仅是代码是否编译成功。
该框架还包括输入模拟,这使得在测试期间可以触发玩家动作,例如移动、按钮按下和摄像机更改。这对于评估只有通过交互才能发现问题的特性尤其重要。所有这些功能都通过统一的 API 公开,使研究团队更容易在同一组任务上比较不同的语言模型。
测试真实开发场景,而不仅仅是代码片段
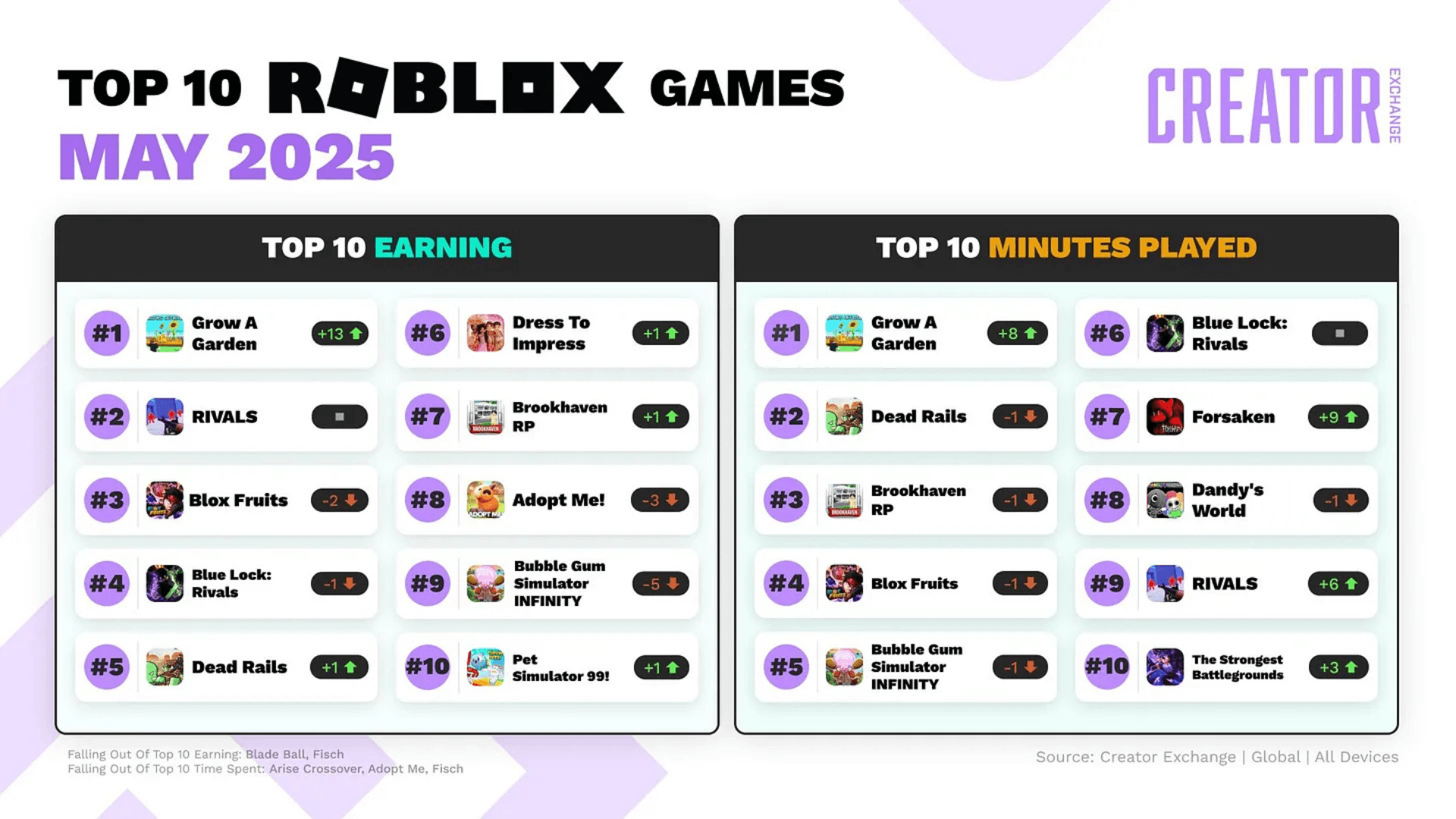
OpenGameEval 基准数据集目前包含 47 个手工制作的测试用例。每个用例都基于常见的 Roblox 开发任务,包括游戏机制、环境设置、动画、用户界面和声音。这些场景由领域专家构建和审查,以确保它们反映真实的创作者工作流程。
与传统的编码挑战不同,这些测试是端到端的。一个成功的 AI 助手必须找到相关脚本,解释现有逻辑,决定新代码的归属,并实现同时适用于客户端和服务器的更改。评分通过可执行单元测试和标准指标(如 pass@k)进行处理,从而使结果可以在模型之间进行复现和比较。
上下文如何改变难度
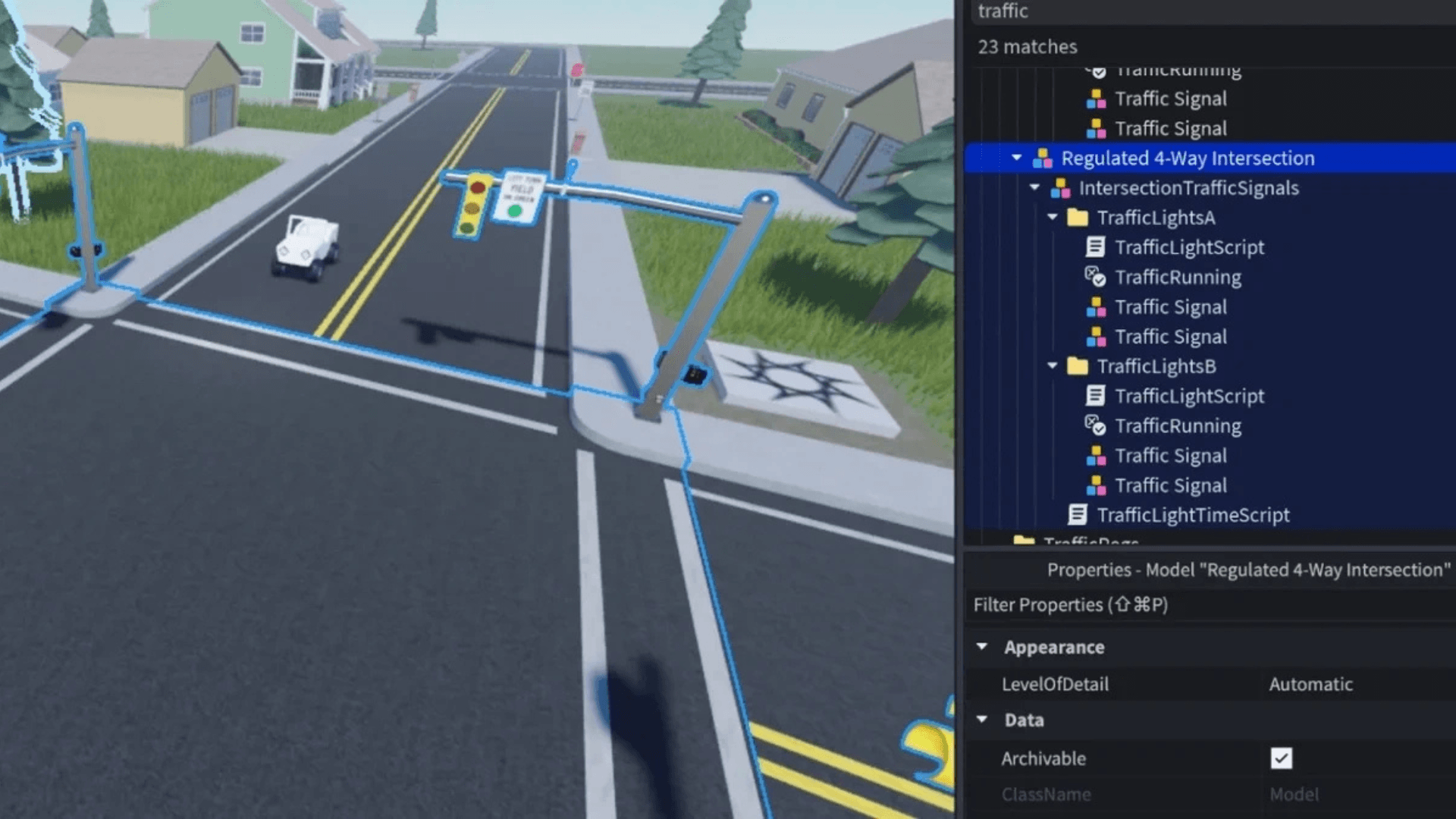
OpenGameEval 的一个显著特点是它专注于上下文变化。同一个提示可以在结构和复杂性不同的多个环境中进行评估。例如,涉及四向交通灯的任务可以在一个空的场景文件、一个人口稠密的郊区场景或一个包含交通和行人信号的设置中进行测试。每个变体都迫使 AI 助手根据体验中已有的内容调整其推理。
更复杂的任务,例如实现生命值恢复系统,要求模型跟踪跨脚本的伤害逻辑,确定更改应该在服务器还是客户端进行,并确保计时和复制正常工作。这些场景旨在揭示 AI 助手是否能够跨多个步骤保持上下文,而不是仅仅依赖于表面模式匹配。
早期结果凸显当前局限性
OpenGameEval 的初步结果表明当前 AI 能力存在明显分歧。模型在涉及直接操作单个实例或属性的原子任务上表现良好。调整玩家跳跃力或配置粒子效果等操作通常能以高可靠性成功。
当任务需要更深层次的上下文推理时,性能会急剧下降。涉及跨脚本协调更改、仔细过滤相关对象或理解多人行为的场景仍然导致成功率较低。这些结果强调了在 AI 助手能够独立可靠地处理复杂的 Roblox 开发任务之前,仍有很大的改进空间。
稳步进展的迹象
尽管面临这些挑战,OpenGameEval 已经捕捉到随着模型演进而出现的改进迹象。在一个涉及更改 Roblox 标志颜色的任务中,早期模型失败了,因为该对象没有明确命名。最近的评估显示,一些模型通过检查其属性和在实例层次结构中的位置,成功识别了正确的对象,而不是仅仅依赖命名约定。
这些渐进的进步表明,AI 助手在游戏环境中的结构化推理能力正在缓慢提高,尽管更广泛的上下文理解仍然不一致。
OpenGameEval 对创作者和研究人员意味着什么
OpenGameEval 旨在服务于 Roblox 创作者和更广泛的 AI 研究社区。一个公开的排行榜展示了不同模型在代码生成和工具使用等类别中的表现。对于研究人员来说,该框架提供了一种在真实游戏引擎环境中运行可复现评估的标准化方法。
展望未来,OpenGameEval 团队计划扩展数据集,完善评估工具,并吸纳创作者社区的反馈。长期目标是为衡量游戏开发中代理式 AI 的进展建立一个共享的参考点,包括与 web3 风格创作者经济相关的未来应用。
请在此处查看 亚马逊上的 Roblox 礼品卡。
在此处了解其他热门的 Roblox 游戏体验:
常见问题 (FAQs)
什么是 OpenGameEval?
OpenGameEval 是一个开源评估框架和基准,旨在直接在 Roblox Studio 内部测试 AI 助手。它衡量模型在实际开发任务而非孤立编码问题上的表现。
OpenGameEval 与其他 AI 基准测试有何不同?
与传统基准测试不同,OpenGameEval 在模拟的 Roblox Studio 环境中运行评估。这使得它能够测试游戏开发中常见的上下文推理、多人行为和有状态交互。
OpenGameEval 包含哪些类型的任务?
该基准包括与游戏机制、脚本编写、环境构建、动画、用户界面和声音相关的任务。许多任务需要跨多个脚本和对象的多个步骤推理。
谁可以使用 OpenGameEval?
该框架是开源的,适用于 AI 研究人员、工具开发者以及为 Roblox Studio 构建或评估 AI 助手的团队。
为什么 OpenGameEval 对 Roblox 创作者很重要?
通过提供透明的性能数据和真实的评估,OpenGameEval 帮助创作者了解 AI 助手的优势和局限性,并跟踪这些工具随时间的改进情况。