
Roblox Studio 越來越成為輔助創作者更快建構遊戲的代理式 AI 助手的測試平台。儘管這些工具已經能夠撰寫腳本、插入素材和修改環境,但要衡量它們在實際開發情境中的表現卻一直很困難。OpenGameEval 旨在透過引入一個原生於 Roblox Studio 的框架,在真實條件下評估 AI 助手,來解決這個問題。
OpenGameEval 由張恬恬、Kartik Ayyar、孫夢莎和 Lynn Gong 開發,是第一個直接圍繞 Roblox Studio 工作流程建構的評估系統。它不是孤立程式碼片段或依賴無狀態提示,而是在模擬的編輯和遊玩階段中執行 AI 模型,這些階段非常接近創作者的實際工作方式。
為何傳統基準測試對 Roblox 不足
大多數現有的 AI 基準測試都專注於具有明確輸入和輸出的狹窄編碼問題。Roblox 開發很少符合這種模式。遊戲建構在持久的 3D 世界中,腳本與物件層級、多人連線網路以及客戶端-伺服器邊界互動。在體驗的某個部分所做的變更,通常取決於散佈在多個腳本和實例中的上下文。
OpenGameEval 的創建是為了應對這些限制。其目標是測試 AI 助手是否能夠在即時的 Roblox 環境中進行推理,理解現有邏輯,並進行在遊戲實際運行時能夠維持的變更。這種方法將評估從理論正確性轉向對創作者的實際可用性。
深入了解 OpenGameEval 框架
其核心是,OpenGameEval 以可重現的方式重建了Roblox Studio 開發環境。每次評估都會模擬編輯時間和遊玩時間的行為,確保物理、網路和多人互動的行為與真實專案中的情況完全相同。這使得評估者能夠觀察 AI 助手的變更在遊戲運行時如何影響體驗,而不僅僅是程式碼是否能編譯。
該框架還包括輸入模擬,這使得在測試期間能夠觸發玩家動作,例如移動、按鈕按下和攝影機變更。這對於評估僅透過互動才能顯現問題的功能尤為重要。所有這些功能都透過統一的 API 暴露,讓研究團隊更容易在同一組任務上比較不同的大型語言模型。
測試真實開發情境,而不僅僅是程式碼片段
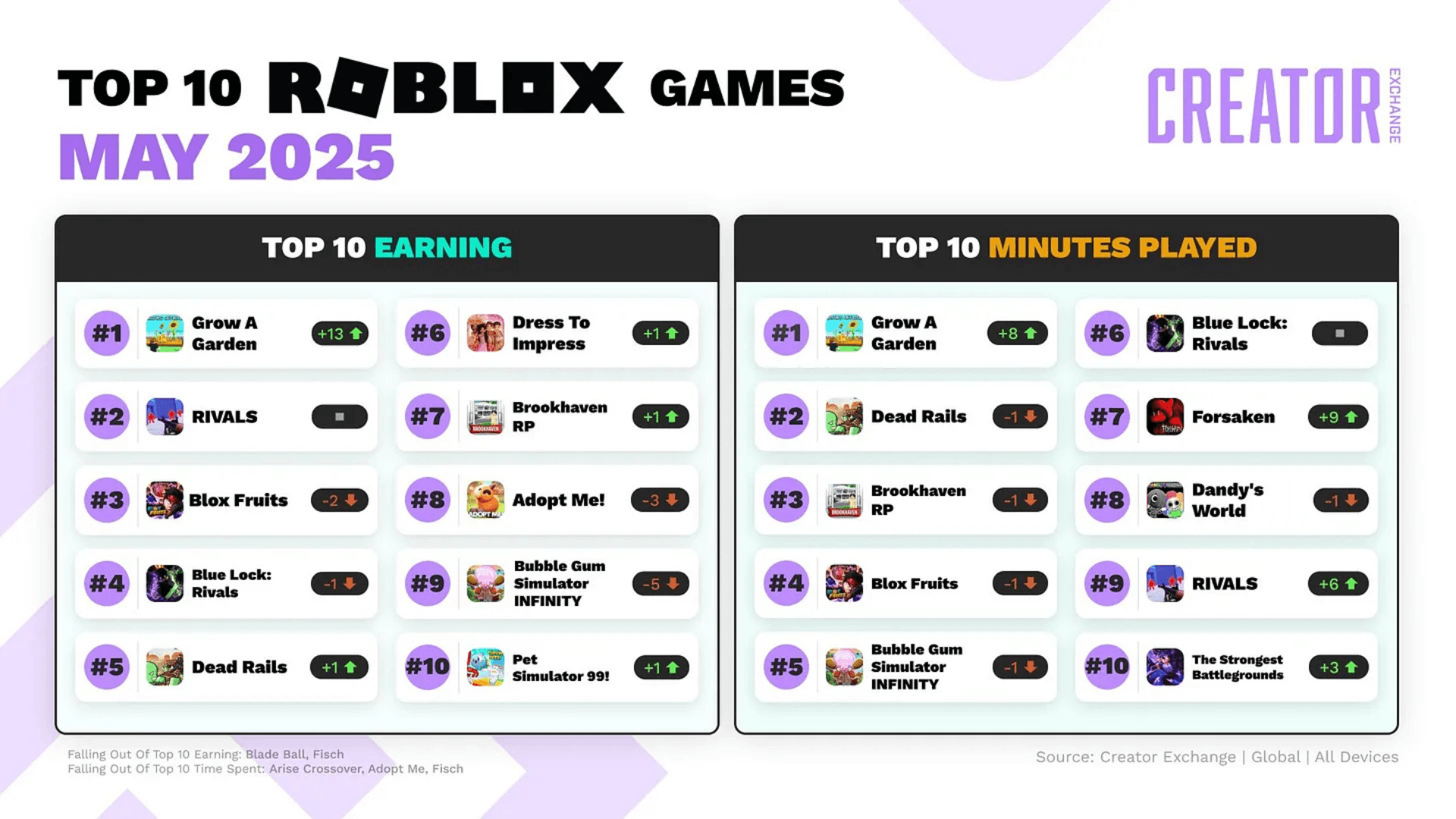
OpenGameEval 基準資料集目前包含 47 個手工製作的測試案例。每個案例都基於常見的 Roblox 開發任務,包括遊戲機制、環境設置、動畫、使用者介面和音效。這些情境由領域專家建構和審查,以確保它們反映真實的創作者工作流程。
與傳統的編碼挑戰不同,這些測試是端對端的。成功的 AI 助手必須能夠定位相關腳本,解釋現有邏輯,決定新程式碼應放置何處,並實施可在客戶端和伺服器之間正常運作的變更。評分透過可執行的單元測試和標準指標(如 pass@k)來處理,從而可以跨模型重現和比較結果。
上下文如何改變難度
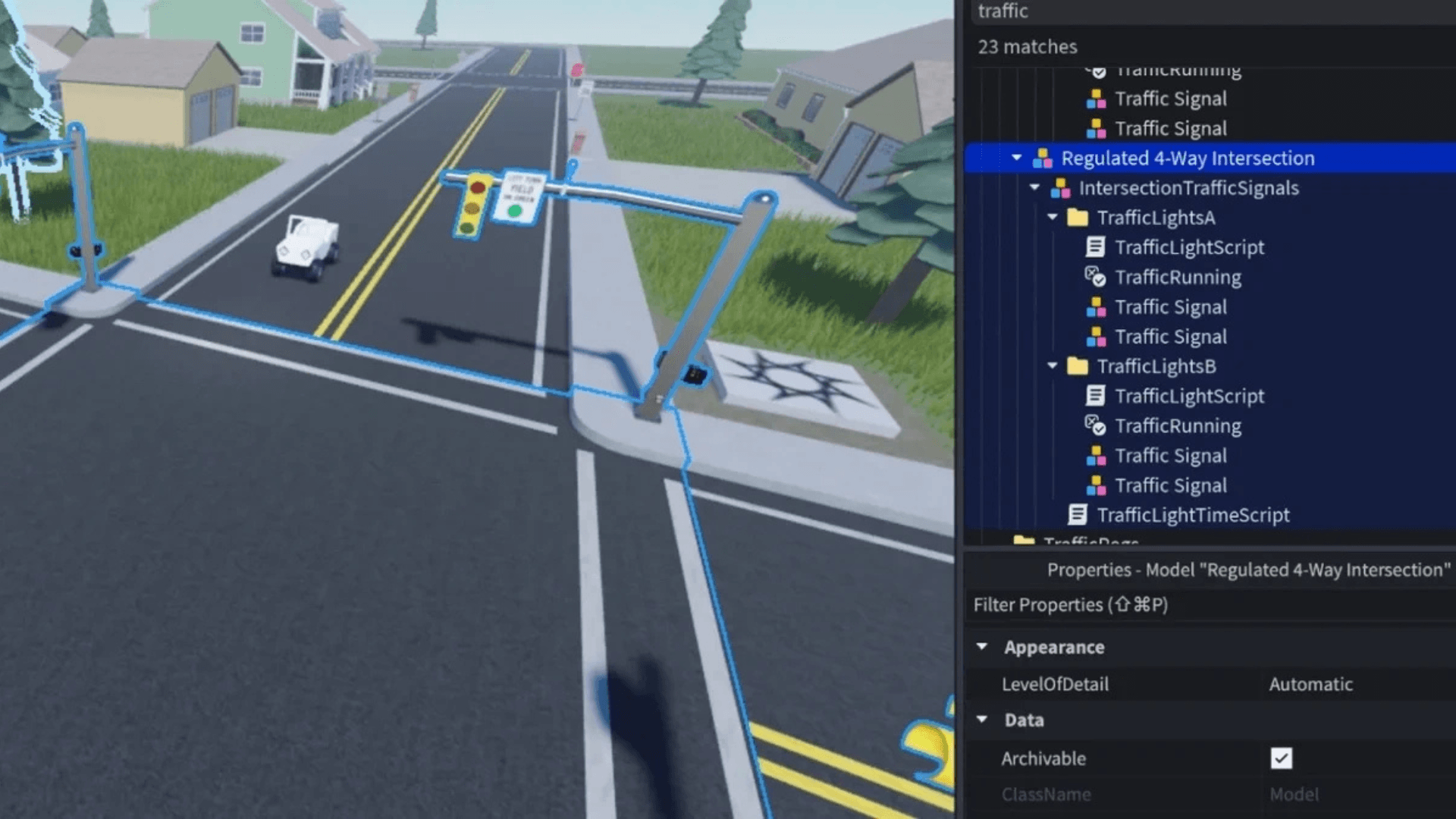
OpenGameEval 的一個決定性特徵是它對上下文變化的關注。相同的提示可以在結構和複雜度不同的多個環境中進行評估。例如,涉及四向交通燈的任務可能會在空檔案、人口稠密的郊區場景或包含交通和行人號誌的設置中進行測試。每次變更都會迫使 AI 助手根據體驗中已有的內容來調整其推理。
更複雜的任務,例如實施生命值再生系統,需要模型追蹤腳本中的傷害邏輯,確定變更應在伺服器端還是客戶端進行,並確保計時和複製正常運作。這些情境旨在揭示 AI 助手是否能夠在多個步驟中保持上下文,而不是依賴表面模式匹配。
早期結果突顯了目前的局限性
OpenGameEval 的初步結果顯示了目前 AI 能力之間存在明顯的鴻溝。模型在涉及單一實例或屬性直接操作的原子任務上表現良好。調整玩家跳躍力或配置粒子效果等操作通常能以高可靠性成功。
當任務需要更深入的上下文推理時,性能會急劇下降。涉及跨腳本協調變更、仔細過濾相關物件或理解多人行為的情境,仍然會產生較低的成功率。這些結果強調了在 AI 助手能夠獨立可靠地處理複雜的 Roblox 開發任務之前,還有多大的改進空間。
穩步進步的跡象
儘管存在這些挑戰,隨著模型的演進,OpenGameEval 已經捕捉到了進步的跡象。在一項涉及更改 Roblox 標誌顏色的任務中,早期模型失敗了,因為該物件沒有明確命名。最近的評估顯示,一些模型能夠透過檢查物件的屬性和在實例層級結構中的位置來成功識別正確的物件,而不是僅僅依賴命名約定。
這些漸進式的進展表明,AI 助手在遊戲環境中的結構推理能力正在緩慢提高,即使更廣泛的上下文理解仍然不穩定。
OpenGameEval 對創作者和研究人員的意義
OpenGameEval 旨在服務於 Roblox 創作者和更廣泛的 AI 研究社群。公開的排行榜提供了不同模型在程式碼生成和工具使用等類別中的表現的可見性。對於研究人員來說,該框架提供了一種標準化的方法,可以在真實的遊戲引擎環境中執行可重現的評估。
展望未來,OpenGameEval 背後的團隊計劃擴充資料集,改進評估工具,並納入創作者社群的反饋。長期目標是建立一個共同的參考點,用於衡量遊戲開發中代理式 AI 的進展,包括未來與 web3 風格創作者經濟相關的應用。
在此處查看 Amazon 上的 Roblox 禮品卡。
在此處了解其他熱門 Roblox 體驗:
常見問題 (FAQ)
什麼是 OpenGameEval?
OpenGameEval 是一個開源評估框架和基準測試,旨在直接在 Roblox Studio 中測試 AI 助手。它衡量模型在實際開發任務上的表現,而不是孤立的編碼問題。
OpenGameEval 與其他 AI 基準測試有何不同?
與傳統基準測試不同,OpenGameEval 在模擬的 Roblox Studio 環境中運行評估。這使得它能夠測試在遊戲開發中常見的上下文推理、多人行為和狀態互動。
OpenGameEval 包含哪些類型的任務?
該基準測試包括與遊戲機制、腳本編寫、環境建構、動畫、使用者介面和音效相關的任務。許多任務需要跨多個腳本和物件進行多步驟推理。
誰可以使用 OpenGameEval?
該框架是開源的,適用於 AI 研究人員、工具開發人員以及為 Roblox Studio 建構或評估 AI 助手的團隊。
為什麼 OpenGameEval 對 Roblox 創作者很重要?
透過提供透明的績效數據和真實的評估,OpenGameEval 幫助創作者了解 AI 助手的優勢和局限性,並追蹤這些工具的改進情況。